Kural embeddings
August 23 2025
Over the last two years, I’ve seen quite a lot of blog posts, videos and explainers about embeddings which initially surprised me. It shouldn’t have, since ‘AI’/LLMs are everywhere now; Developers, students and hobbyists are really excited (as I assume they were about the Web in late 90s/early 2000s and mobile apps in the early 2010s) to understand them and build something using them. Still, it feel surreal for the concept I studied as a Masters student to be the focus of attention for the whole computing industry. There’s too much attention and hype, and I do wonder (with some fear) what a massive financial bubble bursting actually looks like at the micro level in everyday life.
One undeniable positive to come from all the hype around ‘AI’ is much better developer tooling and frameworks for embeddings and neural networks now than in 2017. With Qwen3 multilingual embeddings and Gemini CLI1, I could quickly prototype the first idea that popped in my head: Build a web app that uses a multilingual embedding model to find relevant Thirukural couplets (in Tamil) for user queries in any language. That’s what ‘Kural for your question’ is. I’m pretty happy with the end product, but the retrieval of relevant kural couplets itself with cosine similarity of embeddings is pretty underwhelming.
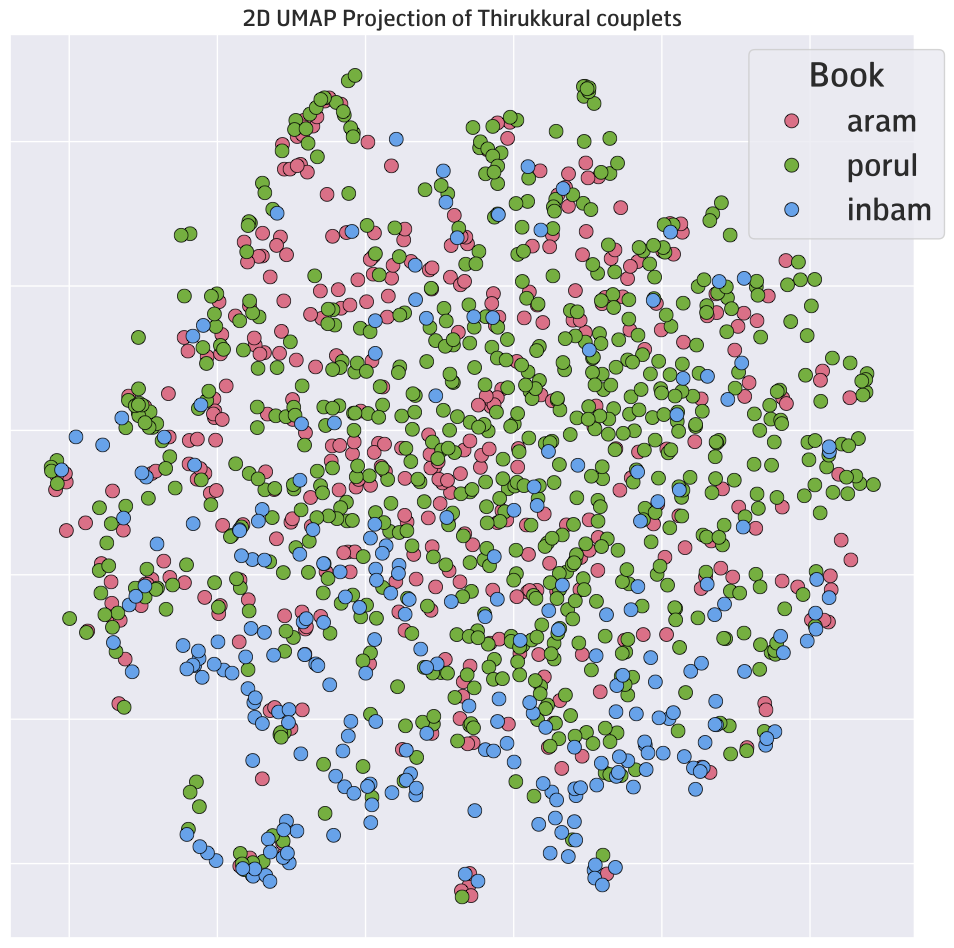
Visualizing the embeddings of all 1330 kurals in 2D using UMAP gives an idea why. There aren’t really any meaningful clusters, with only the Book of Love showing some clear separation from the other two books. The similarity search works sometimes because of certain key words, but lacks any understanding of the intent of the question. For the question What are the duties of a son to his parents? (an undying question for me), only one of the 3 kurals deemed relevant is about the parent-child relationship at all. The larger Qwen3 embedding models might work better, but model training frameworks and data mixtures are more biased towards real-world use cases — my niche, little idea probably doesn’t mesh well with what Qwen3 Embedding was trained to do.
Still feels good to build something, even if underwhelming 🙂.
-
Just like Typeproof — I know its dangerous, but boy is it addictive to build fully functional web apps with just text prompts. I’ve learned more Typescript this way than I have in years, but not as much as I would have learned if I had built these apps from scratch. But I would have never built these web apps from scratch either. ↩
Dangers of the translation period
July 11 2025
I recently watched Fallen Leaves on a flight to Chennai. What a wonderful movie — depressed people talking about love and life in a depressed manner, and yet finding their peace in the end.
A few lines of dialogue caught my attention towards the end of the movie. The main character is solving a crossword puzzle when she utters the meta-linguistic clues out loud:
“Danger.” Six letters.
Threat.
“O positive.” Ten letters.
Blood group.
The above lines are from the English subtitles that I was reading, but Fallen Leaves is a Finnish movie. I wondered how the subtitle translators shifted between cultures when writing the English subtitles for these language-specific clues, so I naturally looked up the original Finnish subtitles:
“Vaara.” Kuusi kirjainta.
Uhka.
“O Positiivinen.” Kymmenen kirjainta.
Veriryhmä.
Kuusi and Kymmenen are the cardinal numbers six and ten in Finnish. But the Finnish word for bloodgroup, Veriryhmä according to the subtitles (and Google Translate) is 9 characters long. However, Finnish plurals are frequently formed with the -t suffix, and the captions might have missed the plural, or the character might have simply said the singular. But, what about Uhka which is just 4 characters?
It is at this point while writing this blog post that I realized she’s solving an English crossword puzzle, and just reading the clues out loud in Finnish🤦🏾♂️. So much for getting excited about an interesting translation puzzle in the wild.
Concurrency in DeTeXt
July 5 2025
I haven’t had a traditional formal CS education, which hasn’t held me back from getting things done with computer programming. However, I have slowly accumulated a long list of blind spots because of the high-level of abstraction modern scripting languages like Python provide. One of these concepts is concurrency. This blog post will be very high-level, but it’s my understanding of these difficult concepts at the moment, and it did help me implement Swift concurrency in my app DeTeXt.1
Sky-high overview
The first misconception I had to forego was the link between concurrency and parallelism. Rob Pike describes the distinction in a succinct way:
Concurrency is about dealing with multiple things at once. Parallelism is about doing multiple things at once.
The dealing with part is important! I didn’t understand the need for this because of how removed I’ve been from low-level programming. YouTuber Core Dumped has [a really good video about concurrency][coredumped], and his explanation finally helped me understand why concurrency is not only important, but crucially the default. Processors execute one instruction at a time — but modern operating systems run hundreds of active processes at any given time. The Operating System (OS) is in charge of figuring out which process should get access to system resources. Modern CPUs are so fast that we’re under the illusion that all processes are running simultaneously2
This fundamental truth about deadling with multiple things that need to get done applies to individual applications/programs as well. Thankfully, application developers can rely on the APIs and abstractions provided by the OS to handle concurrency. For developing applications on Apple platforms in 2025, this means adopting language support for concurrency in Swift.
For my simple app DeTeXt, there were two instances where I needed to deal with concurrency in my code:
- running image recognition with my CoreML model as a separate task on the main thread.
- showing a temporary toast-style pop-up when the user copies a symbol/command/unicode code-point. Once again, this is a task that runs on the main thread.
But what’s a thread? Or a task? And why am I running things on the main thread?
Threads
A process is a program in execution. It has its own program counter, register information, and memory space. However, programs themselves need to do multiple things at once within them. Threads are the abstraction that almost all OSes have settled on to handle concurrency within a process. Every process has a main thread, which is the initial thread where all work first happens. The OS typically initiates subsequent threads based on developer instructions.
For a user-facing mobile application the cardinal rule is that all user interface (UI) work must happen on the main thread. Updating the user interface is a short-term operation that immediately affects the user experience; Users can tolerate waiting for a large download or file save, but the app itself should never crash or lag. Critical operations happen on the main thread, which has OS-level priority for the application.
DeTeXt is a pretty simple app — it doesn’t download or upload anything, all symbols and images are loaded on start-up, and they’re only 10MB anyway. Implementing concurrency in DeTeXt simply meant identifying (and marking) asynchronous functions and possible suspension points (where possible long-running tasks can occur), and instructing the OS to run all asynchronous functions on the main thread, which it was doing anyway.
Actors and Tasks
Swift’s concurrency model doesn’t let us work with threads directly. Instead we work with 2 abstractions — tasks and actors.
A unit of work that we need to handle with concurrency is a task. Fetching web resources, reading/writing from the file system are traditional examples of a task suited for concurrent thinking/processing. For DeTeXt, I defined 2 tasks that encapsulated the 2 asynchronous functions3 mentioned earlier:
- Taking the drawing from the on-screen canvas, pre-processing it, and processing it through the neural net that calculates probabilities for every symbol. The probabilities are stored in a reference type marked Observable —any changes to the underlying data send notifications to SwiftUI views that observe it.
- Displaying the name of the command, or the symbol itself and showing it as a toast-style pop-up on screen for a set, constant period of time, then automatically dismissing it.
Now both of these need to run on the main thread, since they update the UI in both cases. However, both tasks can take undetermined amounts of time to finish. The CPU/GPU/Neural engine might be clogged up doing some other intensive process (very unlikely but possible), and the toast task needs to pause for a set amount of time before finishing. Implementing this in DeTeXt couldn’t have been simpler: package the asynchronous function call to the CoreML model and the toast suspension/sleep as tasks. Now, we need to ensure that both tasks run on the main thread, for which we turn to another abstraction: Actors.
Actors are objects that ensure that only one function has access to mutable data at a time. Their role in concurrency is to avoid data races. The Main Actor is in charge of updating all the data that updates the UI. Since the only mutable data in my app pertains to the UI, I simply needed to mark the two asynchronous functions with the @MainActor attribute, instructing the OS that while there may be suspension points in these two functions, both of them impact the UI, so ensure that these functions only run on the Main Actor. The Main Actor abstracts over the main thread — they’re very similar, and the differences have more to do with low-level implementation details.
Fin
I learned a lot about concurrency and asynchronous functions while re-writing my app to use Swift’s new concurrency features. You can view the actual code changes on the GitHub repo of course. To be honest, writing this blog post took more time than actually learning and implementing Swift concurrency in my app! I love explainer blog posts and videos, so I figured I’d give a shot at writing my own, for me.
-
I didn’t need to add concurrency as it turned out, but it was a good excuse to learn the underlying concepts. ↩
-
On CPUs with multiple cores, multiple processes do run simultaneously. But even the beefiest CPU from Apple has ‘only’ 32 cores. I had 869 active processes when I was writing this post. ↩
-
Asynchronous functions run as part of some task — the task abstraction enables structured concurrency, which I haven’t explored yet. ↩
Pride hiding prejudice
Jan 25 2025
“How many of you are actually proud of being Indian?”
Dutifully, me and a few others raised our hands to this pointed question by our social sciences teacher. I believe we were in ninth or tenth standard, so in our mid-teens. Her reply to the handful of raised hands was just as biting — I don’t believe you.
She was right; at least, about us not being truly proud. We raised our hands because we knew it was the right thing to do, not because we were truly proud of our country. I couldn’t have described with any words what ‘being proud of your country’ meant at that time. There were empty quotes and calls to duty, but duty to whom? My recollection was that we were taught to serve our country by not questioning authority or tradition. Pride in one’s country, as my social science teacher (and most adults around me at the time) understood it, precludes questions, criticisms and introspection of cultural practices. But pride that requires conformance, fear or unquestioning respect of authority is not worth having. Considering the strict, authoritarian and traditional environment of school where our teacher was an active participant, I’ve no doubt this was the pride she sought. I know now that I want no part of this pride.
She wouldn’t believe me today if I said I was proud of my country, because we diverge on what pride means. I take pride in the people in India and around the world who question authority, injustice and fight for freedom from suffocating power structures. I’m proud of people who try to interrogate their privilege and try to unlearn their indifference to suffering. One day, I hope to be truly proud of my country and myself, as I do the necessary, hard work that is required of anyone walking down this path.
Developer's Cut
Jan 11 2025
I was watching HBomberguy’s video on Director’s cuts a few days ago, when my mind discovered a connection to something else I’d read, as it tends to do when I’m marinating on the couch after dinner. Hbomberguy references an article ‘Uncertain Glory’ by Greg Solman, published in Film Comment magazine, 1993. The article is a terrific read; here’s my favorite passage (and most relevant to my larger point):
Viewing film art as perpetually subject to update and correction, political or other, says something about the director’s relationship to his work…Director’s cuts are both futile and wrong-headed. In a way, they redress artistic grievances by treating movies as mere product. In this country, an inalienable right to change as an artist doesn’t extend to changing art and, therefore, art history.
I don’t think the argument is that Director’s cuts should be outlawed as a concept — rather, treating cinema as subject to revision and change (which can be marketed) has consequences for the creative pursuit of film-making and how the audience responds to the art-form. Which brings me to this reply by John Gruber to Ken Kocienda’s post on Mastodon:
For as long as I’ve known him — and I’ve known him going on, jeez, almost 25 years now — @brentsimmons has said his favorite part of programming is deleting code. I think that’s perhaps the fundamental thing about programming that makes it unique as an art form. No other creative medium I can think of has that quality.
While this reply is about deleting code, Kocienda’s original post describes the way most (good) software developers view their code. We learn not to grow attached to our code, and to focus on constant updates and refinement. But what does this say about our relationship to our work, as Solman raised about Director’s cuts?
I’m not going to argue that programming isn’t art; I’ve already written about how the Is this art? argument isn’t very interesting. However, two things are true at once:
- Programming is fundamentally revisionist — you have to maintain and update your code-base or it usually won’t work sooner or later. There’s always bugs and inefficiencies to fix. A software project not being actively maintained means death. Programming might have artistic qualities and it is definitely a creative pursuit — but the intended product of your program has to work and be stable for some time to be useful.
- However, the fact that programming is fundamentally a revisionist creative pursuit means there are consequences to embracing it whole-heartedly. Big Tech releases half-baked software all the time under the Beta label. Video-game companies release unfinished video games and market it as Early access. Just because software is amenable to updates and refinement doesn’t mean our standards for good software releases should go down, but there’s where we are now.
Drawing a connection between the unintended consequences of Director’s cuts and revising code gives us a new lens to understand how we approach building software, but it shouldn’t be taken as a directive to update or revise code less. I think knowledge of the unintended consequences of the nature of one’s creative pursuit or medium is valuable in of itself. It helps us make better decisions when writing code and building software.