Nuance Fucks
3 August 2020
I recently re-read Kieran Healy’s 2015 paper deriding the abundance of ‘nuance’ in U.S Sociological research. I love this paper because it forced me to think about how I may fall into some of the ‘nuance traps’ that he identifies, especially the nuance of the fine-grain:
First is the ever more detailed, merely empirical description of the world. This is the nuance of the fine-grain.
Is there a similar phenomenon of nuance rising in Computational Linguistics? Anecdotally, I do see the words nuance and fine-grain more often in new papers and talks. There is a way to verify this — the ACL Anthology provides a bibliography of articles with their titles and abstracts dating back to 1960s. Searching the bibliography using some simple regular expressions, we see that the proportion of articles that mention the words nuance or fine-grain in their titles or abstracts have indeed risen in the last 10 years (there were few mentions before 2000 so I’ve excluded them).
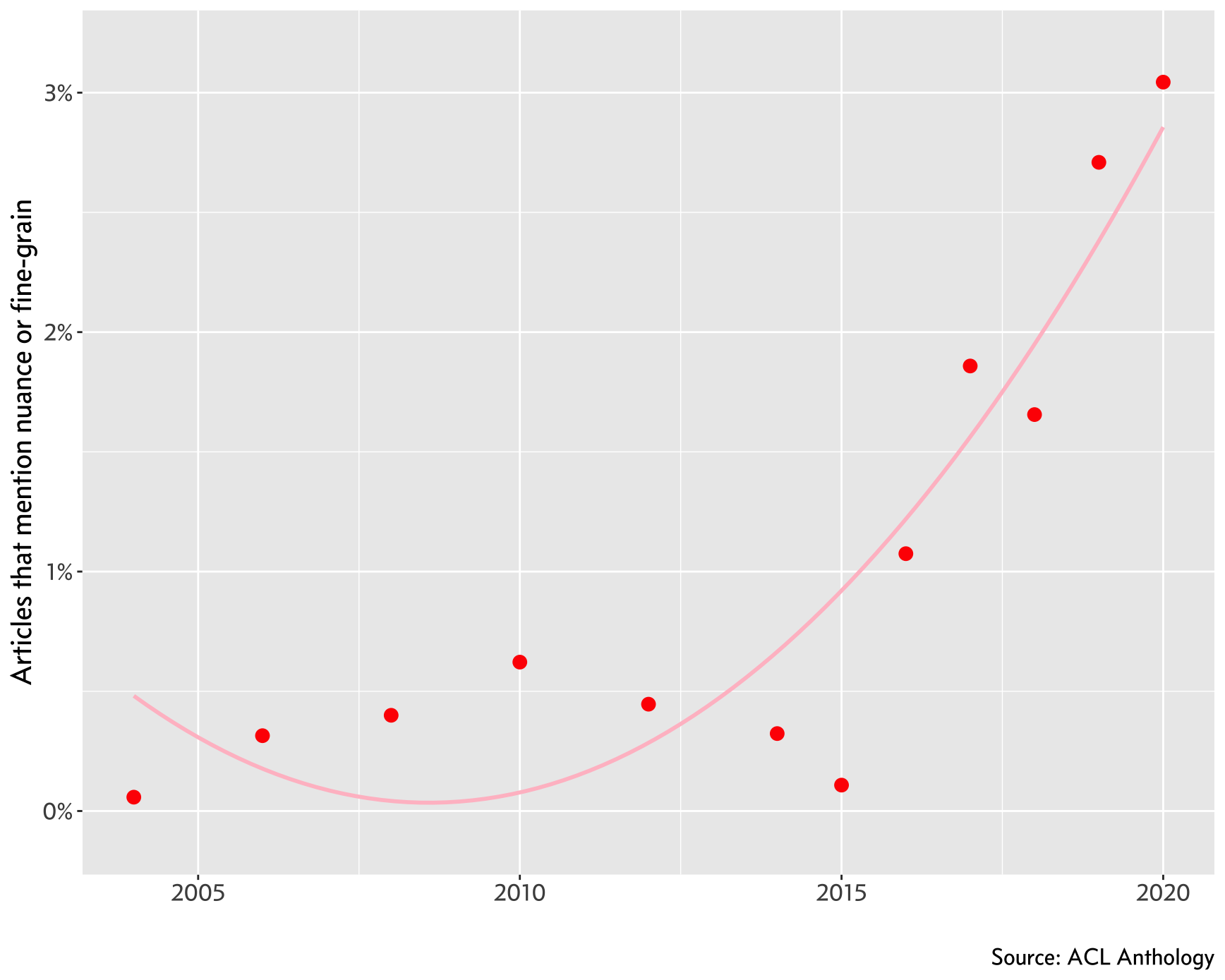
However, the bib file has some issues – older articles are generally
missing their abstracts, so we only have their title to search from. Top people
are trying to fix the missing abstract field issue, but until then,
we can recalculate the proportion of ‘nuanced’ articles by only considering
entries that have an abstract field in the bibliography. We observe the same
trend:
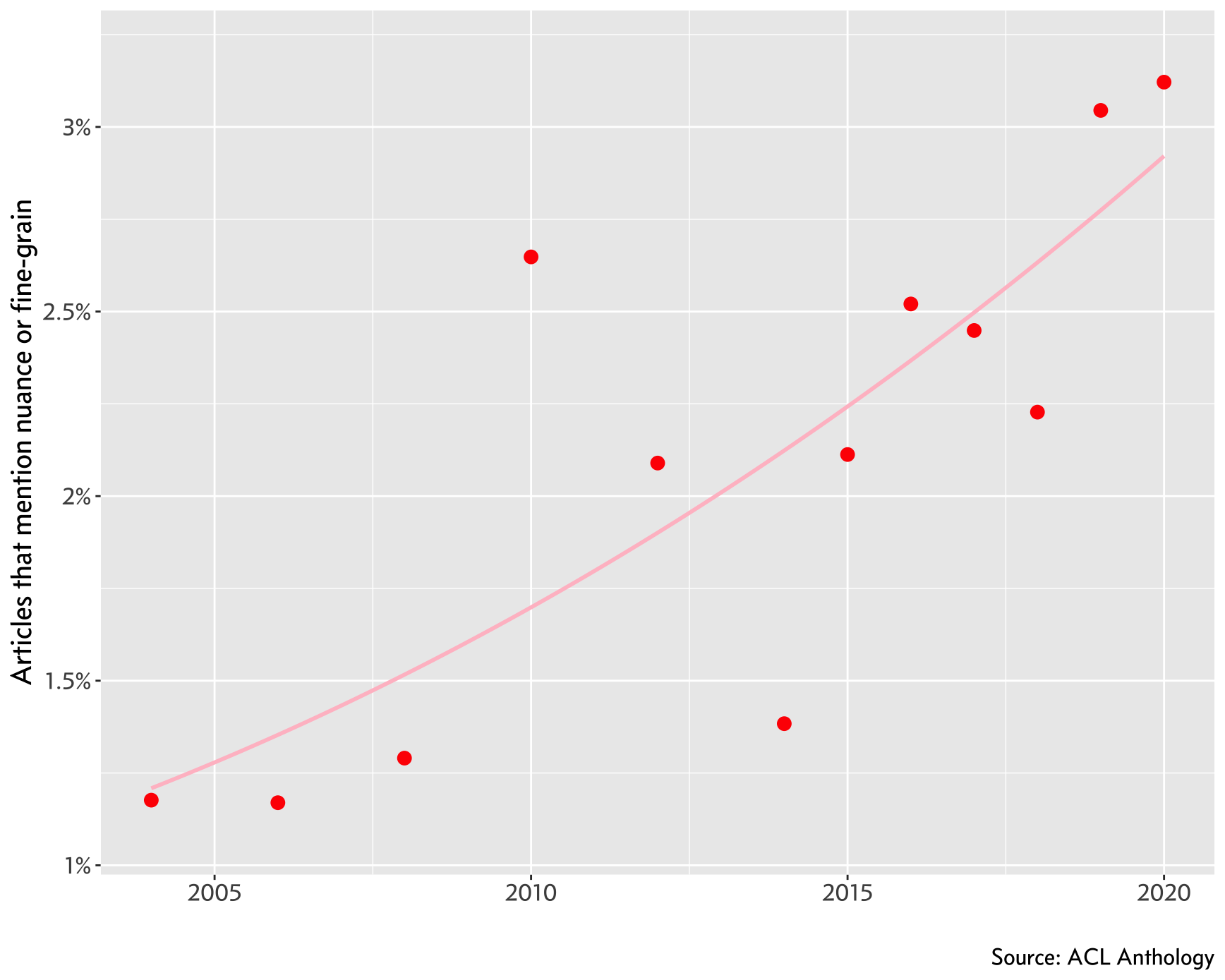
I don’t think that all of these papers fall into the nuance traps that Healy describes. Nor do I think that this trend of exploring the subtleties and richness of language is bad for computational models and theories of language – my first paper is about exploring nuance within the theory of generics! However, I do fear that I regularly fall into the trap of valuing some research more because it is more nuanced.