Dark and Stormy
January 31 2026
I’m especially proud of this: I wrote a paper on sentences from the Bulwer-Lytton Fiction Contest(BLFC). I don’t recall how I found the BLFC, but I knew these sentences were too good to not study further. All credit to Scott and EJ Rice for organizing this wonderful contest for many, many years, and graciously giving me permission to study the resource they curated.
As it turns out, just having data isn’t enough to get a paper out. Neither is having fun ideas about how you’d analyze it. Working on it for months on end despite multiple dead-ends, and finding a wonderful collaborator in Laura were key to finishing this paper. I hope people find the resource and paper interesting, and a jumping-off point for further work!
One of my favorite analyses in the paper is the final section, where we look at ‘deviant’ adjective-noun (AN) bigrams. Deviancy is hard to define, but it arises when a phrase is grammatically well formed but the overall meaning is weird or incongruent (colorless green, residential steak, warm equation) The term is from a 2016 paper by Eva M. Vecchi where they collect paired acceptability judgements for about 25K ANs, building distributional models that predict deviancy extremely well.
We found that Bulwer-Lytton sentences contain many more deviant ANs than control sentences (from openings to novels and humor datasets). What was surprising was that LLM generated Bulwer-Lytton sentences contain even more deviant ANs compared to BLFC entries. To derive the count of AN bigrams, I used the excellent infini-gram API to query the DCLM pre-training corpus containing over 3 trillion words. Figure 5 from our paper shows this effect beautifully: the BLFC corpus contains many more rare/deviant ANs than control sentences. Further, 80% of ANs generated by DeepSeek occurred less than 1000 times in the DCLM corpus, compared to 40% of ANs in the BLFC corpus, and 25-30% in control.
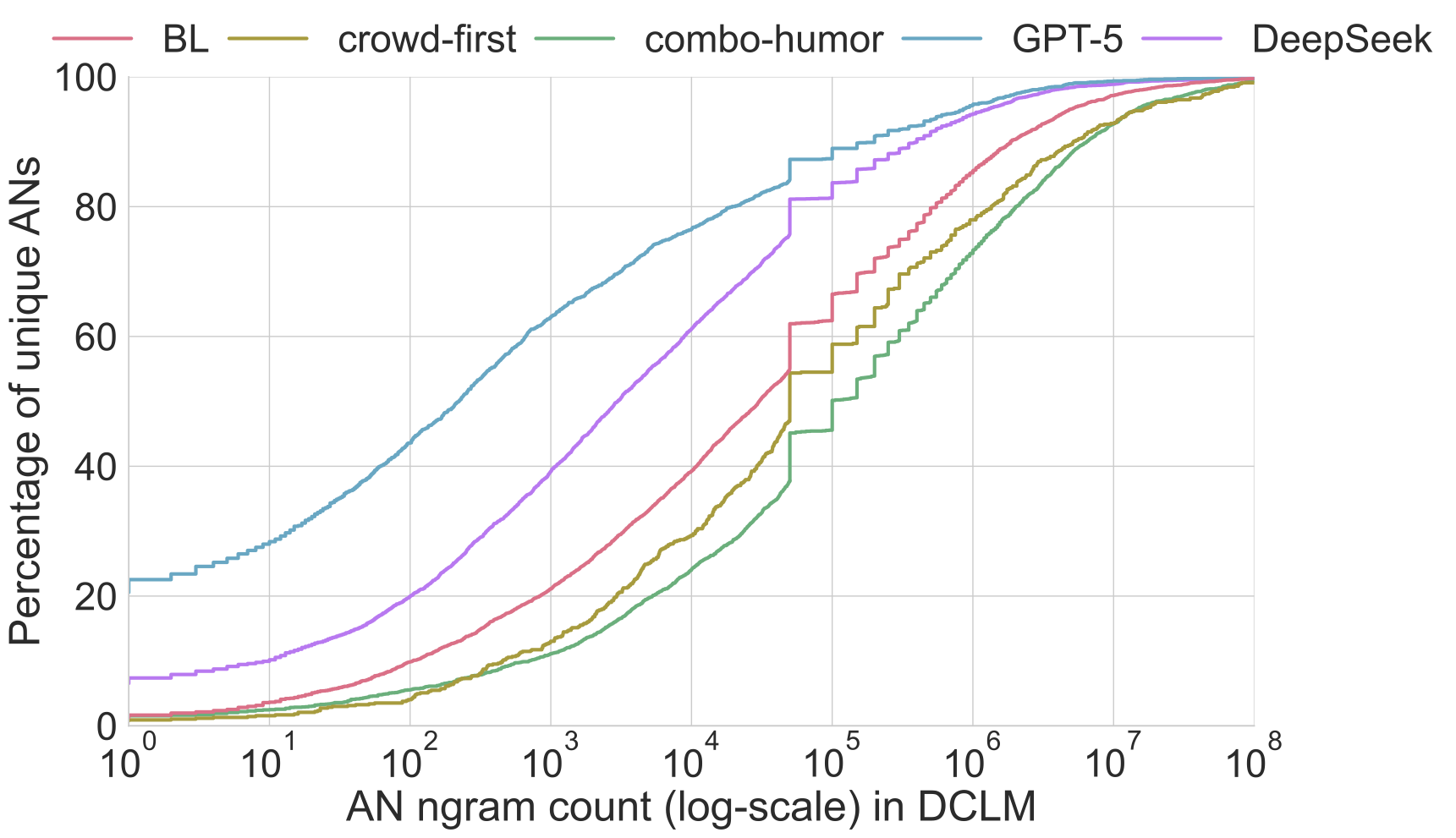
This got me thinking back to Eva M. Vecchi’s original dataset of deviant ANs. They quantified these ANs as unattested by looking at a corpus of 3 billion words— tiny by the standards of today’s pre-training corpora. What if we query their count against the DCLM pre-training corpus? The figure below validates that most of these ANs are indeed, deviant. 80% of them occur less than 1000 times in the corpus.
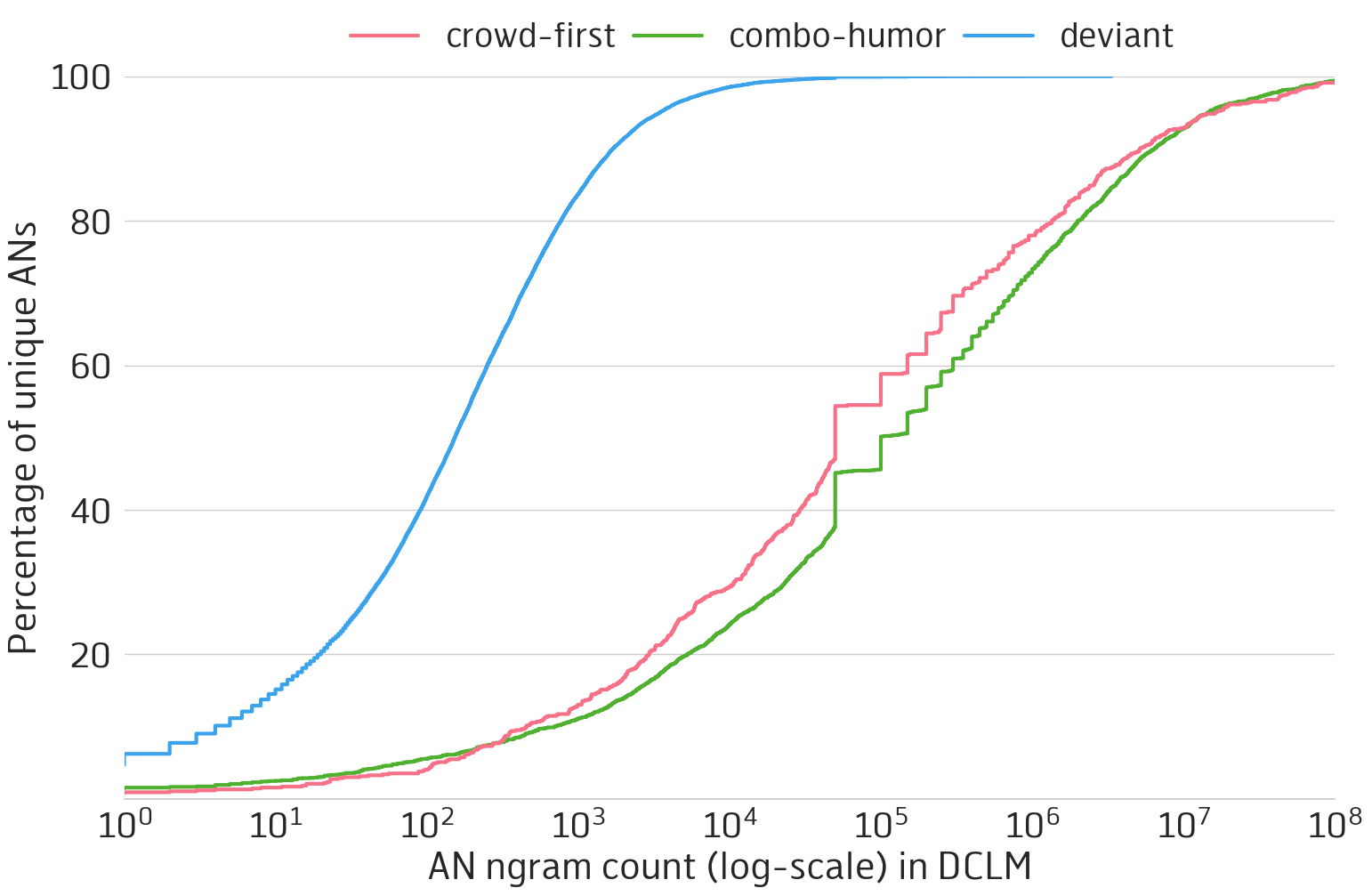
My counting methodology isn’t perfect. infini-gram just queries raw strings, so some entries are over/under-counted for various reasons: misspellings, polysemy (meaning its not really an adjective-noun bigram), a missing prefix/suffix, etc. But I don’t think it takes away from the story these figures tell. Then I got another idea with all the deviant ANs I had at my disposal.
So here it is — a webpage that gives you a random deviant adjective noun bigram (I filtered the list down to 3994 ANs that occured less than 10 times in the DCLM corpus). Here are some of my favorites from randomly reloading the page: bold airfield, classical bowler, informal fate, nuclear suitability.